c++20 协程与 io_uring 初探:一个最简单的 echo server
写这篇的初衷是想动手实践一下 io_uring 和 c++20 协程。
这个版本的代码由 github.com/frevib/io_uring-echo-server 改造而来,是希望通过在 io_uring 的基础上,尝试实现最基本的协程 IO 模式,然后进行性能对比。之前的版本使用了一个 event loop 的模式,并通过 io_uring 的 IORING_OP_PROVIDE_BUFFERS 参数和 IORING_FEAT_FAST_POLL 参数,实现了零拷贝和内核线程的 polling,不需要额外的系统调用开销。
本文在 io_uring-echo-server 的基础上增添了一个简易的协程实现,完整的 demo 代码实现在这里:github.com/yunwei37/co-uring-WebServer/blob/master/demo/io_uring_coroutine_echo_server.cpp
协程实现
原先的代码包含一个 event loop,大致是这样(忽略具体细节),进行 IO 和完成 IO 的逻辑是完全分开的:
1 |
|
这里简单介绍一下协程的实现方式。使用协程的 co_await 关键字,可以让 IO 的异步回调变得更自然,例如对于一个连接进行 echo,我们的协程版本可以写成这样:
1 | conn_task handle_echo(int fd) { |
这里 handle_echo 里面的 read 和 write,和同步的调用编写方式基本一样,只是在前面使用了 co_await 关键字,指明了该函数是个协程。
根据 C++ 的规范,这里的协程是无栈协程,需要实现一个 task 和 promise_type,例如:
1 | struct conn_task { |
以 write 为例,它返回一个 awaitable 对象:
1 | auto echo_write(size_t message_size, unsigned flags) { |
实际上,在运行到 write 调用时,由于 awaitable 对象中的 await_ready 返回 false,协程会在调用 await_suspend 之后停下来,回到主循环,在主循环中,当我们接收到 write 的调用时,只需要简单地通过协程句柄让协程继续运行:
1 | .... |
此时协程会从 await_resume() 中继续运行,并将 await_resume 的返回值作为 write 的返回值。具体细节可以参考仓库中的代码实现。
benchmark
- 运行环境:
Linux ubuntu 5.11.0-41-generic #45~20.04.1-Ubuntu SMP Wed Nov 10 10:20:10 UTC 2021 x86_64 x86_64 x86_64 GNU/Linux- vmware 16, 8GB ram,Intel Core i7-10750H,2 cores,4 Logical processors;
- 编译指令:
g++ io_uring_echo_server.cpp -o ./io_uring_echo_server -Wall -O3 -D_GNU_SOURCE -luring -std=c++2a -fcoroutines - benchmark tool:https://github.com/haraldh/rust_echo_bench,使用 taskset 将其与一个核心绑定:
io_uring with coroutine
source:github.com/yunwei37/co-uring-WebServer/blob/master/demo/io_uring_coroutine_echo_server.cpp
request/sec, 60 sec:
| clients | 1 | 50 | 150 | 300 | 500 |
|---|---|---|---|---|---|
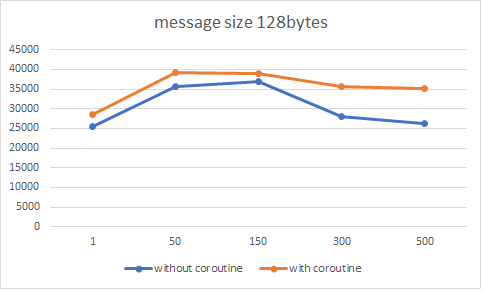
| 128 bytes | 28635 | 39206 | 38985 | 35658 | 35013 |
| 512 bytes | 34693 | 40981 | 40536 | 36040 | 35251 |
| 1000 bytes | 22304 | 46619 | 43915 | 35162 | 34618 |
io_uring without coroutine
source:github.com/yunwei37/co-uring-WebServer/blob/master/demo/io_uring_echo_server.cpp
request/sec, 60 sec:
| clients | 1 | 50 | 150 | 300 | 500 |
|---|---|---|---|---|---|
| 128 bytes | 25405 | 35736 | 37010 | 28093 | 26337 |
| 512 bytes | 26207 | 36847 | 39342 | 32921 | 38786 |
| 1000 bytes | 26077 | 36865 | 39312 | 35115 | 52847 |
至于 epoll,原作者有进行过 epoll 和 iouring 的对比,可以参考这里: benchmarks
可能是机器性能的原因,在多线程情况下提升并没有很大。
简单画个图对比一下,可以发现仅仅是简单应用协程的情况下,不仅异步编程模型清晰了不少,性能也获得了一点提升:
测试脚本:
1 |
|
reference
c++20 协程与 io_uring 初探:一个最简单的 echo server